This time I explore the inbuilt ETL feature called Data Flow in Oracle DV ( DVD in my case).
To start with first go to Data Sources and Create Data Flow.

It will prompt for Data Source. We can select a Data Source or alternatively we add a source by either clicking on the '+' icon on top to add data or 'Add Data' option on the lefthand side menu.

Now let me, explore the left-hand side menu. These are the basic ETL activities those we can perform.

I start with selecting Sample Order Lines excel as a source.

My objective is to load the Customer data into Customer dimension.

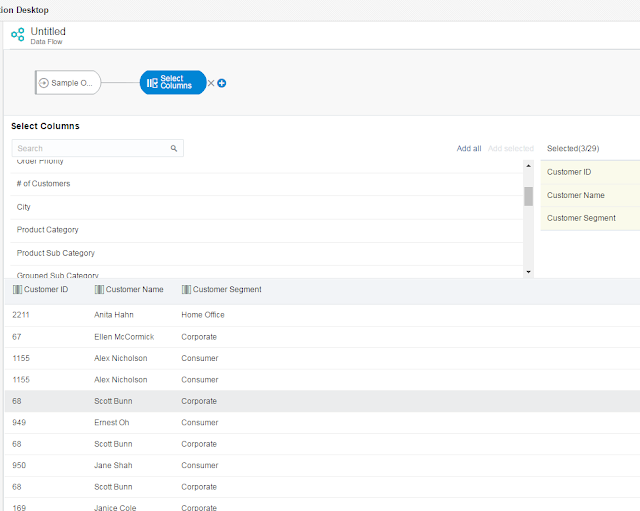
Therefore first I need to select the Customer columns, and I use 'Select Columns'.

And I select 'Customer ID', 'Customer Name', 'Customer Segment'.
Next, I use 'Rename Columns' to match the target column names.

And now I define the target table.

I save and execute the Data Flow.

Now I open the table in DB and check the loaded data. It has loaded 9000 rows.

However, there is a problem. There are duplicate records. And as I have stated earlier my objective was to load data for Customer dimension. I need to get distinct rows only.

To do that, I have added one more column 'CUST_COUNT' which is nothing but 'Customer ID' only.

And I add aggregation 'Count' on CUST_COUNT.

I do not do any further change, and as I do not have any target column as CUST_COUNT, it is not going get loaded in the target. But by having an aggregation I am using group by other columns, and that in turn is eliminating the duplicate rows.

Now I truncate the target table and rerun the Data Flow, and this time the result is as desired.

There are multiple other options and we can use expressions also, which we might cover in a later post.
To start with first go to Data Sources and Create Data Flow.

It will prompt for Data Source. We can select a Data Source or alternatively we add a source by either clicking on the '+' icon on top to add data or 'Add Data' option on the lefthand side menu.

Now let me, explore the left-hand side menu. These are the basic ETL activities those we can perform.

I start with selecting Sample Order Lines excel as a source.

My objective is to load the Customer data into Customer dimension.

Therefore first I need to select the Customer columns, and I use 'Select Columns'.

And I select 'Customer ID', 'Customer Name', 'Customer Segment'.

Next, I use 'Rename Columns' to match the target column names.

And now I define the target table.

I save and execute the Data Flow.

Now I open the table in DB and check the loaded data. It has loaded 9000 rows.

However, there is a problem. There are duplicate records. And as I have stated earlier my objective was to load data for Customer dimension. I need to get distinct rows only.

To do that, I have added one more column 'CUST_COUNT' which is nothing but 'Customer ID' only.

And I add aggregation 'Count' on CUST_COUNT.


Now I truncate the target table and rerun the Data Flow, and this time the result is as desired.

There are multiple other options and we can use expressions also, which we might cover in a later post.



No comments:
Post a Comment